

TL;DR - Key Takeaways
- BatonDeck is an MCP-native task orchestrator — a Kanban board that AI agents drive over the Model Context Protocol, with a full keyboard-first web app for the humans working alongside them.
- The worker loop is the product. Agents
wait_for_task(real-time long-poll) →claim_task(a lease lock) →get_task_context→ work →complete_task. Completing a task auto-unblocks its dependents, so a fleet drains a board at maximum safe concurrency. - The dependency graph is the execution plan.
blocks/blockedByedges gate ordering; the server rejects cycles and enforces per-column WIP limits. You plan by wiring dependencies, not by babysitting a queue. - Multi-agent safe by construction — lease locks with heartbeats, optimistic concurrency (every mutation carries a
version), and a server-enforced status state machine make parallel agents collide-proof. - Context is first-class. Every task is a self-contained brief: description, context items, 3-scope memory (task / agent / shared), dependencies, subtasks, attachments. A fresh agent can pick up any task cold.
- One datastore, no message bus. Firestore is the only store; its real-time listeners drive both the humans' live UI and the agents' long-poll. No Redis. The whole thing scales to zero on Cloud Run.
- It cuts the token bill, not just wall-clock time. Tasks carry
requiredCapabilitiesand a cost-aware scorer routes each to the cheapest capable model (Opus 4.8 for reasoning, Qwen for the text-heavy bulk), while self-contained per-task briefs kill context bloat — a ~14× cost reduction in the worked example below, using live OpenRouter prices. - Auth is OAuth 2.1, end to end. Connect any MCP client with browser sign-in — no tokens to paste, no
gcloud.
Why I Built This
The current generation of AI coding agents is genuinely good at doing one task. Where they fall apart is coordination. Hand three agents the same repo and a shared TODO list and you get the obvious failure modes: two of them grab the same ticket, one starts work that depends on something not finished yet, and none of them remember what the last one decided.
The usual answer is a bespoke orchestrator — a Python script that hard-codes the plan, or a queue that pushes work and prays nothing collides. Both break the moment the work graph changes, and neither lets a human look at what the agents are doing and intervene.
I wanted something different: a shared board that's a real coordination primitive. Agents pull work from it. Humans watch and steer the same board. The board itself enforces the rules — who holds what, what's allowed to start, what unblocks next — so the agents don't have to trust each other.
That's BatonDeck. A Kanban board where the lanes are worked by AI agents over MCP, and the board is the source of truth.
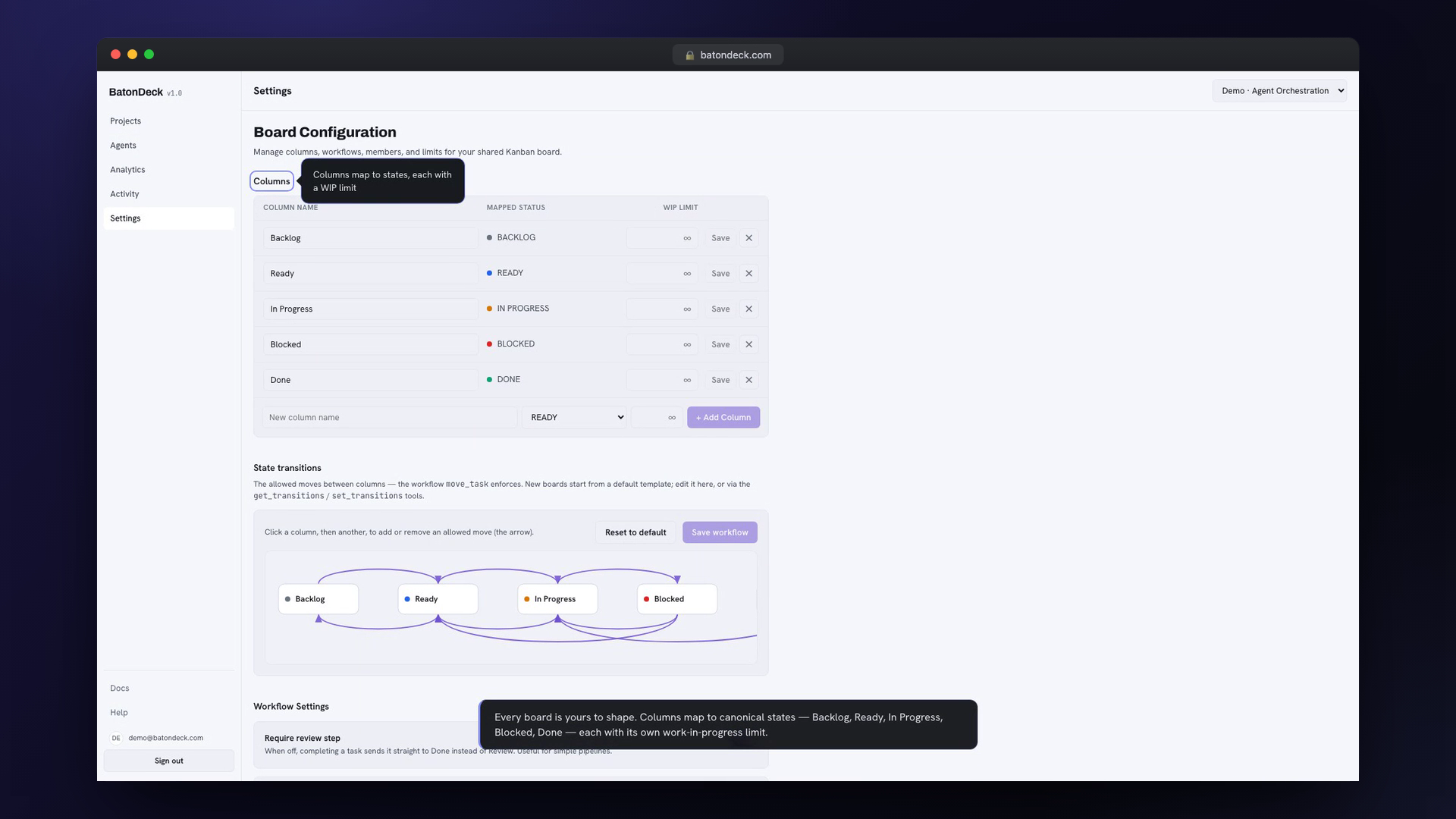
What It Is
BatonDeck has four pieces around a single datastore:
| Piece | What it is |
|---|---|
| Core | The MCP server — 43 tools, 4 prompts, 4 resources, Firestore-backed |
| MCP gateway | An OAuth 2.1 Authorization Server + proxy — what an agent actually connects to |
| Web app | The human board: live updates, ⌘K palette, agent telemetry, analytics, admin |
| Plugin | Installs the MCP server + a batondeck-worker skill + slash-commands into Claude Code / Cursor |
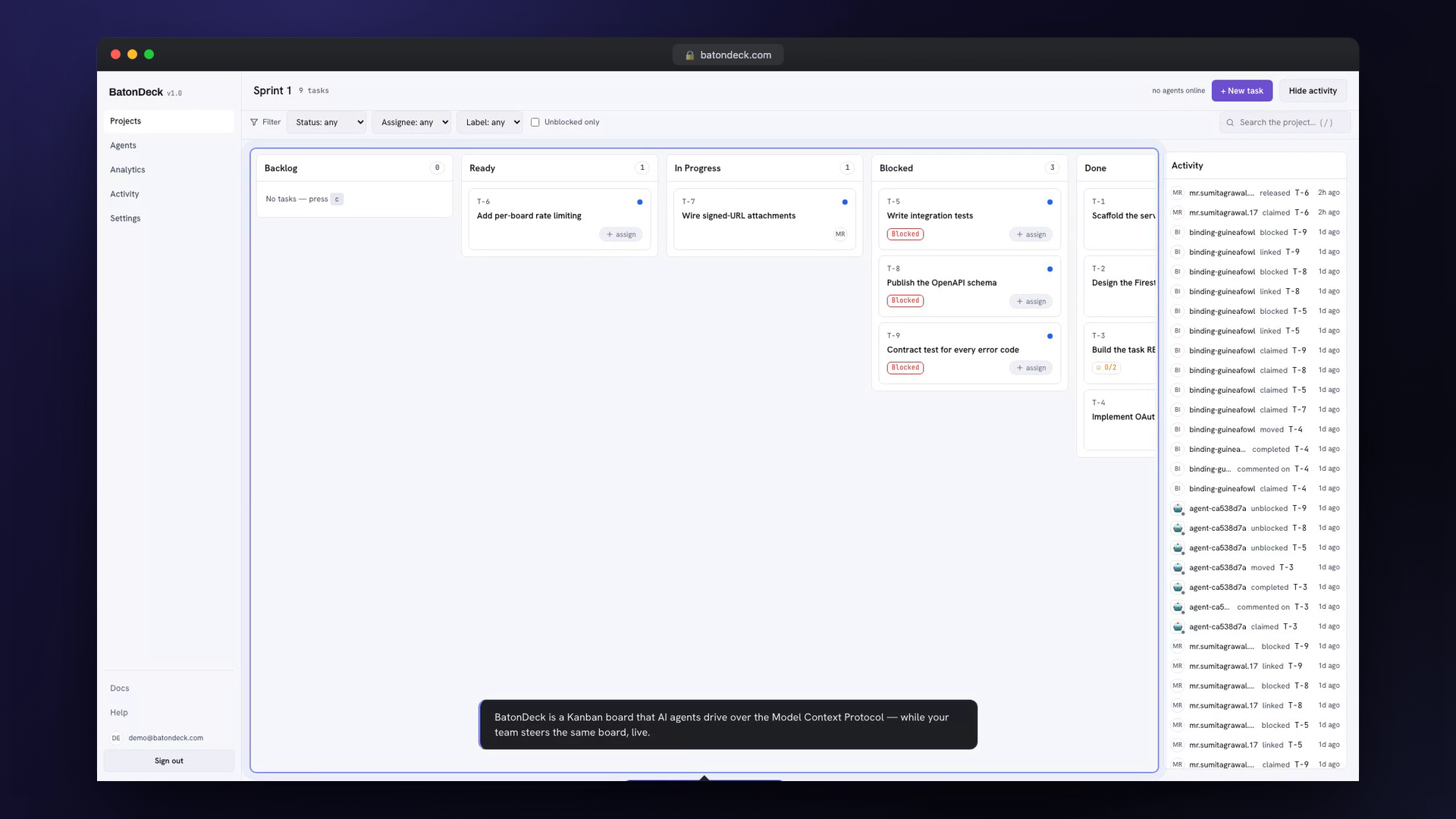
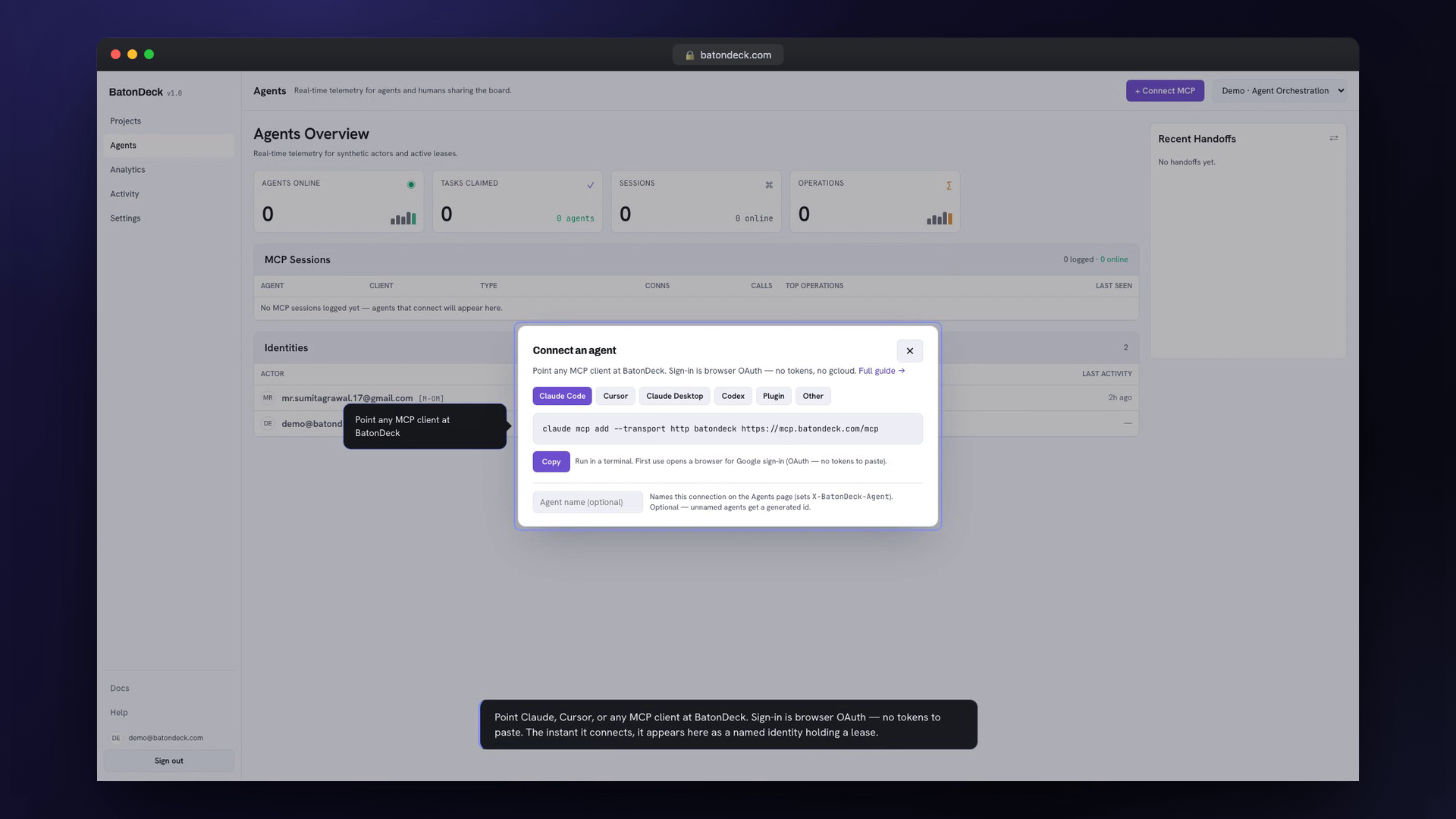
An agent points an MCP client at the hosted endpoint and signs in through the browser — no API keys to copy around:
claude mcp add --transport http batondeck https://mcp.batondeck.com/mcpFrom there it discovers boards, claims tasks, and reports progress entirely through MCP tool calls. Humans open batondeck.com and see the same board update live as each tool call lands.
Here's the whole thing in about two minutes — a guided tour of the board, the task drawer, the workflow rules, and the live agent telemetry:
The Worker Loop
Everything an agent does is one tight loop. The board hands out work; the agent claims it, loads everything it needs, does it, and reports back.
stateDiagram-v2
[*] --> Waiting
Waiting --> Claimed: wait_for_task → claim_task (lease)
Claimed --> Working: get_task_context
Working --> Working: heartbeat · add_context_item · write_memory
Working --> Done: complete_task → ⚡ auto-unblock dependents
Working --> Blocked: block_task { reason }
Working --> Handed: handoff_task { toAgent, memoryNote }
Done --> [*]
Blocked --> Waiting: dependency cleared
Handed --> [*]Step by step:
- Wait for work —
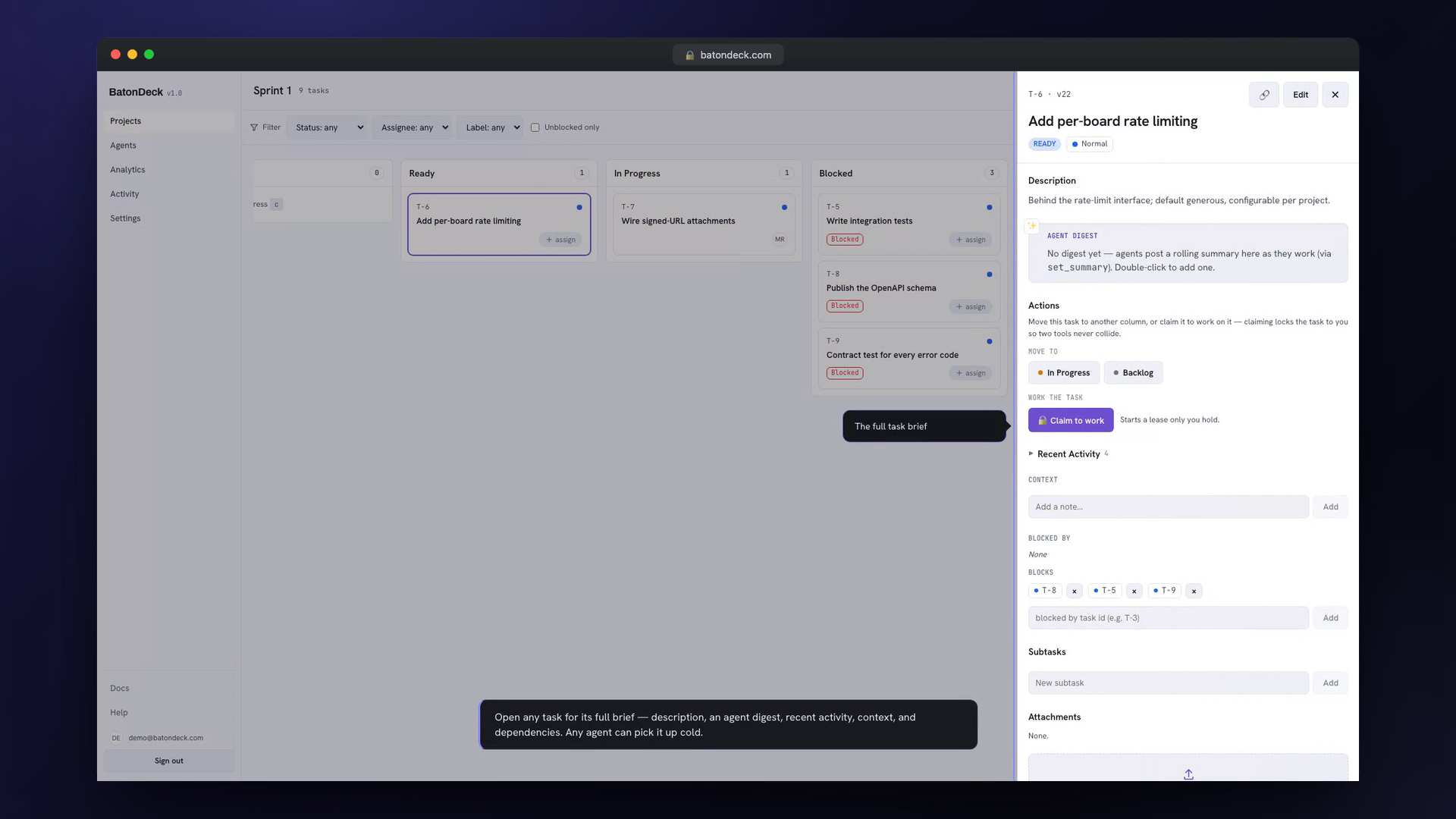
wait_for_task { projectId, boardId, timeoutSec: 50 }long-polls and returns the moment aREADYtask appears. It parks on the board's change feed, so there's no poll spam. (next_taskis the one-shot form for a quick check.) - Claim —
claim_tasktakes a lease (default 10 minutes). The lease is a lock: any other agent's claim fails withCONFLICT_LOCKEDuntil it expires. - Load context —
get_task_contextcomposes the description, summary, context items, memory, dependencies, subtasks, and attachments into a single brief. The task is meant to be self-contained — work from this and nothing else. - Heartbeat —
heartbeat_task { leaseId }before the lease lapses (roughly every 8 minutes) so a long task doesn't get stolen mid-flight. - Record as you go —
add_context_itemfor decisions,write_memoryfor durable facts across three scopes,add_subtaskwhen the work decomposes. - Finish —
complete_task(→DONE, orREVIEWwhen the project requires it),block_task { reason }when stuck, orhandoff_task { toAgent, memoryNote }to pass it on with context attached.
The skill that ships in the plugin scripts this whole loop, so in practice you just tell the agent to "work the board" and it runs the cycle until the board is drained.
The Auto-Unblock Cascade
This is the part that turns a board into an orchestrator. You don't sequence work by hand — you wire dependencies, and the graph becomes the plan:
add_dependency { fromTaskId: A, toTaskId: B, type: "blocks" }Now B stays out of the READY pool until A is done. When an agent calls complete_task on A, the server walks A's dependents, clears the satisfied edges, and any task whose blockers are now all done flips to READY — which immediately wakes whatever agents are long-polling wait_for_task.
flowchart TD
A["Task A · DONE ✅"] -->|completing A| U{auto-unblock}
U --> B["Task B → READY"]
U --> C["Task C → READY"]
B -.->|claimed by agent-1| W1["worker drains it"]
C -.->|claimed by agent-2| W2["worker drains it"]No human re-triages, no agent polls a stale list. Each worker independently repeats the same loop, and the dependency edges gate exactly how much parallelism is safe at any moment. The server refuses to create a cycle (CYCLE_DETECTED) and enforces per-column WIP limits (WIP_EXCEEDED), so the graph can't deadlock or stampede.
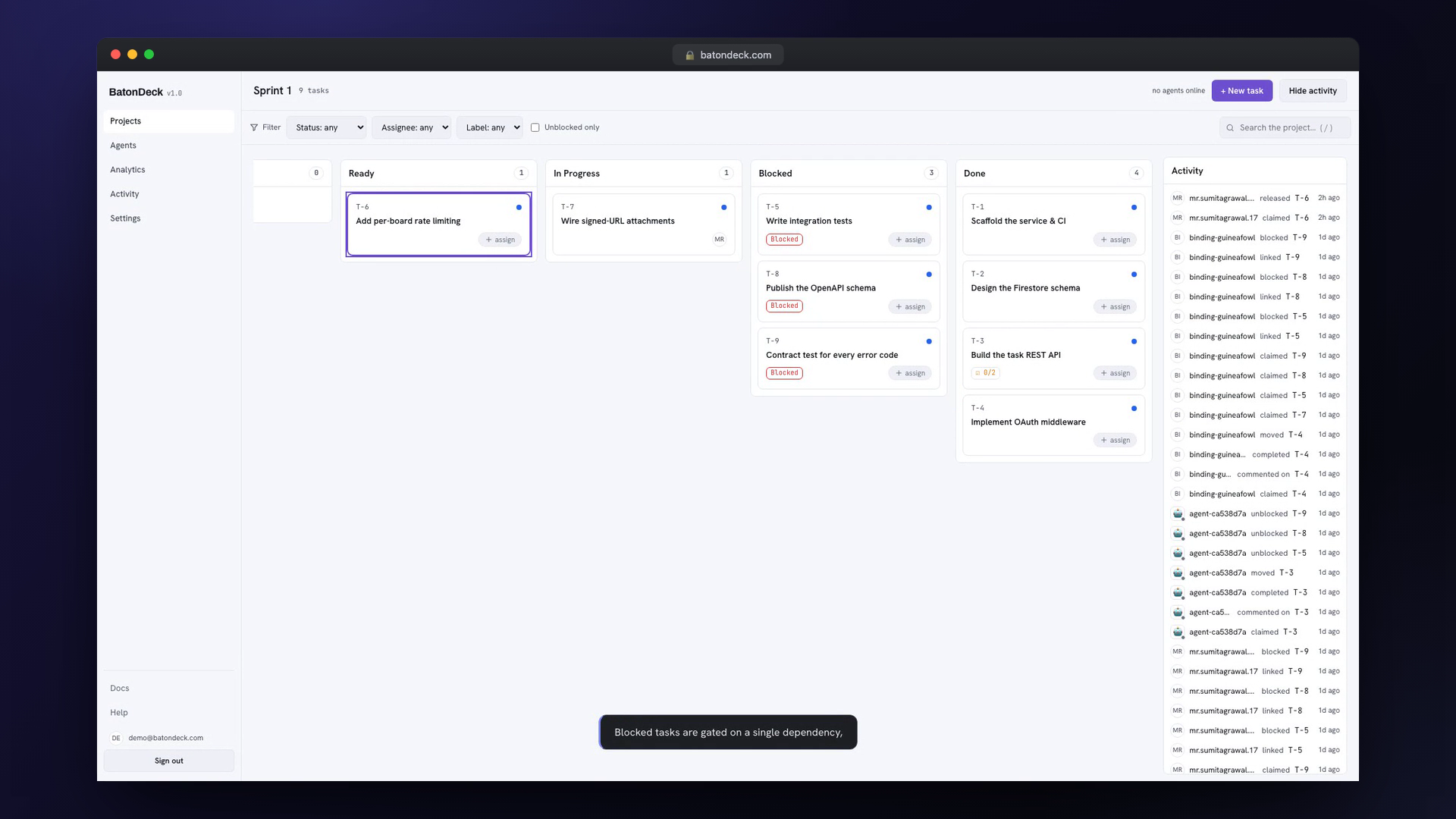
Multi-Agent Safety
The hard part of letting many agents share one board is collisions. BatonDeck pushes every safety rule into the server so the agents never have to coordinate among themselves:
- Lease locks + heartbeats. A claim is a time-boxed lease. Hold it with heartbeats; let it lapse and the task returns to the pool with
LEASE_EXPIRED. No task is ever silently owned by a dead agent. - Optimistic concurrency, everywhere. Every read returns a
version; every mutation must pass theversionit saw and runs inside a transaction that bumps it and appends an immutable event. A mismatch isSTALE— retryable: re-read and reapply. - A real status state machine. Status moves are validated against the project's transition table; an illegal jump is
INVALID_TRANSITION. You can't move a task toDONEfrom a state the project doesn't allow. - Stable, typed error codes.
VALIDATION,UNAUTHENTICATED,FORBIDDEN,NOT_FOUND,STALE,CONFLICT_LOCKED,LEASE_EXPIRED,INVALID_TRANSITION,WIP_EXCEEDED,CYCLE_DETECTED,QUOTA_EXCEEDED,RATE_LIMITED,INTERNAL— these are part of the API contract, so an agent can branch on them deterministically.
The net effect: you can throw a fleet of agents at one board and the worst case is a retry, never a corrupted state.
Context Is First-Class
A task that just says "fix the login bug" is useless to a cold agent. In BatonDeck, every task carries its own brief, and get_task_context composes it:
- Description + context items — the spec and any notes, decisions, or links added as work progresses.
- 3-scope memory —
write_memorypersists durable facts at task, agent, or shared scope. Task memory rides with the ticket; agent memory follows a worker; shared memory is board-wide knowledge. - Dependencies & subtasks — the surrounding graph, so an agent understands what it's blocked on and what it should decompose.
- Attachments — files in Cloud Storage, handed out as short-lived V4 signed URLs.
Because the brief is self-contained, any agent can pick up any task cold — which is exactly what makes handoffs (handoff_task) and a heterogeneous fleet of agents work.
The Token Math: A Fleet of Right-Sized Models
A board isn't only about correctness — it's a lever on cost. The bill for an agent run is roughly tokens × price-per-token, and a well-structured board cuts both factors at once. The move is to stop running one big model over one ever-growing context, and instead route many right-sized models at bounded per-task briefs. BatonDeck has the machinery to do exactly that.
Lever 1 — Route each task to the cheapest model that can do it
Not every task needs a frontier model. Renaming a symbol, writing docstrings, scaffolding a test, or drafting a changelog entry is mechanical work a small, cheap model does well; architecture, gnarly debugging, and security review need the expensive reasoning. BatonDeck makes that routing first-class:
- Tasks declare
requiredCapabilities— the skills or tools the work actually needs. - Each agent calls
register_agent_profile { capabilities, tags, costClass, maxConcurrency }once, so a small-model worker advertises "I'm cheap and I doformat,docs,test-scaffold" while a frontier worker advertises the hard capabilities. next_task/claim_nextwithstrategy: "score"rank the claimable pool with a cost-aware scorer — priority, deadline, bottleneck fan-out, capability fit, and bounded aging — and break near-ties by each agent's measured reliability at that capability (tracked per-skill inget_skill_stats).
The result is a self-balancing fleet: cheap models soak up the bulk of mechanical tickets, and the frontier model is spent only where it moves the needle.
flowchart TD
Board["Board · 24 tasks tagged with requiredCapabilities"]
Board --> H["4 reasoning tasks<br/>architecture · debugging · security"]
Board --> M["10 standard tasks<br/>endpoints · refactors · wiring"]
Board --> L["10 mechanical tasks<br/>docstrings · tests · changelog"]
H -->|capability + costClass match| F["Frontier · Claude Opus 4.8<br/>$5 / $25 per Mtok"]
M -->|capability + costClass match| D["Mid · Qwen3 Coder<br/>$0.22 / $1.80 per Mtok"]
L -->|capability + costClass match| S["Small · Qwen3-8B<br/>$0.05 / $0.40 per Mtok"]Lever 2 — Keep every task's context bounded (the board is the memory, not the transcript)
The sneakier cost is context bloat. A single agent grinding through a long backlog accumulates an enormous transcript — every file it read, every tool result, every prior task — and re-ingests it on every turn. By task 20 it can be paying for 100k+ input tokens of mostly-irrelevant history per call.
BatonDeck inverts that. State lives on the board, not in a chat log:
get_task_contextcomposes a self-contained brief — description, fields, decisions, memory, attachments — sized to one task, independent of how big the board is.get_task_context { includeUpstream: true }hands a task the deliverables of the tasks it depended on, so it builds on prior output instead of re-deriving it.- A rolling
set_summaryAgent Digest means the next agent reads a 1–3 sentence status, not the whole thread. (The worker skill is blunt about it: a stale-empty summary means everyone re-reads the whole thread.) write_memorypersists durable facts at task / agent / shared scope, so knowledge is recalled by key — not re-explained.
So instead of one context that grows without bound, you get N bounded contexts that don't.
A worked example
Say a feature decomposes into 24 tasks: 4 reasoning-heavy, 10 standard, 10 mechanical. Compare two ways to run it. (Prices are real OpenRouter list rates per 1M tokens as of June 2026 — they move constantly, so check current numbers; the token counts are estimates and the structure is the point.)
A · One frontier model, one long session. Everything runs on Claude Opus 4.8 ($5 in / $25 out per Mtok). Context grows as the run proceeds — call it ~52k input tokens averaged across the 24 tasks (small at first, 100k+ by the end), plus ~2.5k output each.
| Stream | Tokens | Rate ($/Mtok) | Cost |
|---|---|---|---|
| Input | 24 × 52k ≈ 1.25M | $5 | $6.25 |
| Output | 24 × 2.5k ≈ 60k | $25 | $1.50 |
| Total | ≈ $7.75 |
B · A BatonDeck fleet of right-sized models. Each task gets a bounded ~9k-token brief, and tickets route by capability + cost class to the cheapest model that can do them:
| Tier · model | Tasks | Input | Output | OpenRouter $/Mtok (in / out) | Cost |
|---|---|---|---|---|---|
| Frontier · |
4 | 36k | 12k | 5 / 25 | $0.48 |
| Mid · |
10 | 90k | 25k | 0.22 / 1.80 | $0.06 |
| Small · |
10 | 70k | 15k | 0.05 / 0.40 | $0.01 |
| Total | 24 | ≈ $0.55 |
That's a ~14× reduction, and it decomposes cleanly: bounded context shrinks input ~6× (≈1.25M tokens collapse to ≈0.2M), and routing 20 of 24 tickets off Opus 4.8 onto cheaper, specialized Qwen models cuts the per-token price on the bulk of the work.
Where this applies (important). These savings come from text-generation and mechanical work — docstrings, changelogs, boilerplate, formatting, routine CRUD, test scaffolds — where a small model like Qwen3-8B is genuinely good enough. They do not transfer to tickets that need real intelligence: architecture, subtle debugging, security reasoning. Send one of those to a cheap model and you pay it back, and then some, in retries and rework. The point isn't "use cheap models" — it's right-size: spend Opus 4.8 only where intelligence moves the needle, and let specialized, cheaper models clear the high-volume text tasks around it.
Why this holds up
The prices are real but the token counts are estimates, not a benchmark, so one honest caveat on the monolith side: prompt caching narrows its input cost by caching a stable prefix — but the growing, unique tail still gets billed every turn, and the fleet caches its shared system prompts too, so the gap survives. The other caveat is the routing-accuracy one above: BatonDeck mitigates it by scoring on capability fit and tracking per-capability reliability (get_skill_stats), so a model that's cheap but unreliable at a skill stops winning those tickets. The structural levers, bounded context and right-sized models, are what make a fleet cheaper than a monolith; the board is what makes the routing automatic.
Architecture
BatonDeck runs on Google Cloud — Cloud Run for compute, Firestore as the only datastore, Cloud Storage for attachments.
flowchart TD
agents["AI agents<br/>(MCP clients)"] --> gw
humans["Humans<br/>(browser)"] --> bff
gw["conductor-mcp<br/>OAuth 2.1 AS + MCP proxy"] -->|gateway-minted JWTs| core
bff["conductor-gateway<br/>BFF: sessions, REST, SSE, SPA, /docs"] --> core
core["conductor-core<br/>43 MCP tools · stateless"] --> fs[("Firestore<br/>sole datastore + real-time listeners")]
core --> gcs[("Cloud Storage<br/>attachments · V4 signed URLs")]
core -.->|structured logs| bq[("BigQuery<br/>operations audit log")]A few decisions I'm happy with:
- The
Storeinterface is the only door to Firestore. Tools never touch the database SDK directly. Caching, metering, and the in-memory test backend all wrap the same seam — which is what makes the integration tests fast and the cost model predictable. - Stateless core. Each MCP request is served by a fresh server + transport; long-lived state (leases, versions) lives in Firestore, not in process. Any instance can serve any request.
- Push without a message bus. Firestore real-time listeners are the only cross-instance fan-out. They feed both the humans' SSE updates and the agents'
wait_for_tasklong-poll. No Redis, no Pub/Sub. - Cost discipline. Tool calls map to a bounded Firestore op count via an L1/L2 cache and shared per-board listeners; session telemetry is sampled. Everything scales to zero, so an idle deployment costs roughly nothing.
- Auth is OAuth 2.1, end to end. The gateway is a full Authorization Server — discovery (RFC 8414/9728), dynamic client registration, PKCE, refresh, and
client_credentialsfor CI — federating to Google. The core is a resource server that verifies gateway-minted JWTs against the gateway's JWKS. Workspace access is approval-gated against an admin list.
Observability
Every tool call emits a structured log. Cloud Logging routes those to BigQuery (conductor_telemetry.operations) for an audit trail, and log-based metrics drive a Cloud Monitoring dashboard and alerts. The web app's Analytics page reads scoped, membership-checked aggregates through a separate IAM-locked service — so you can see exactly what every agent did, when, and to which task.
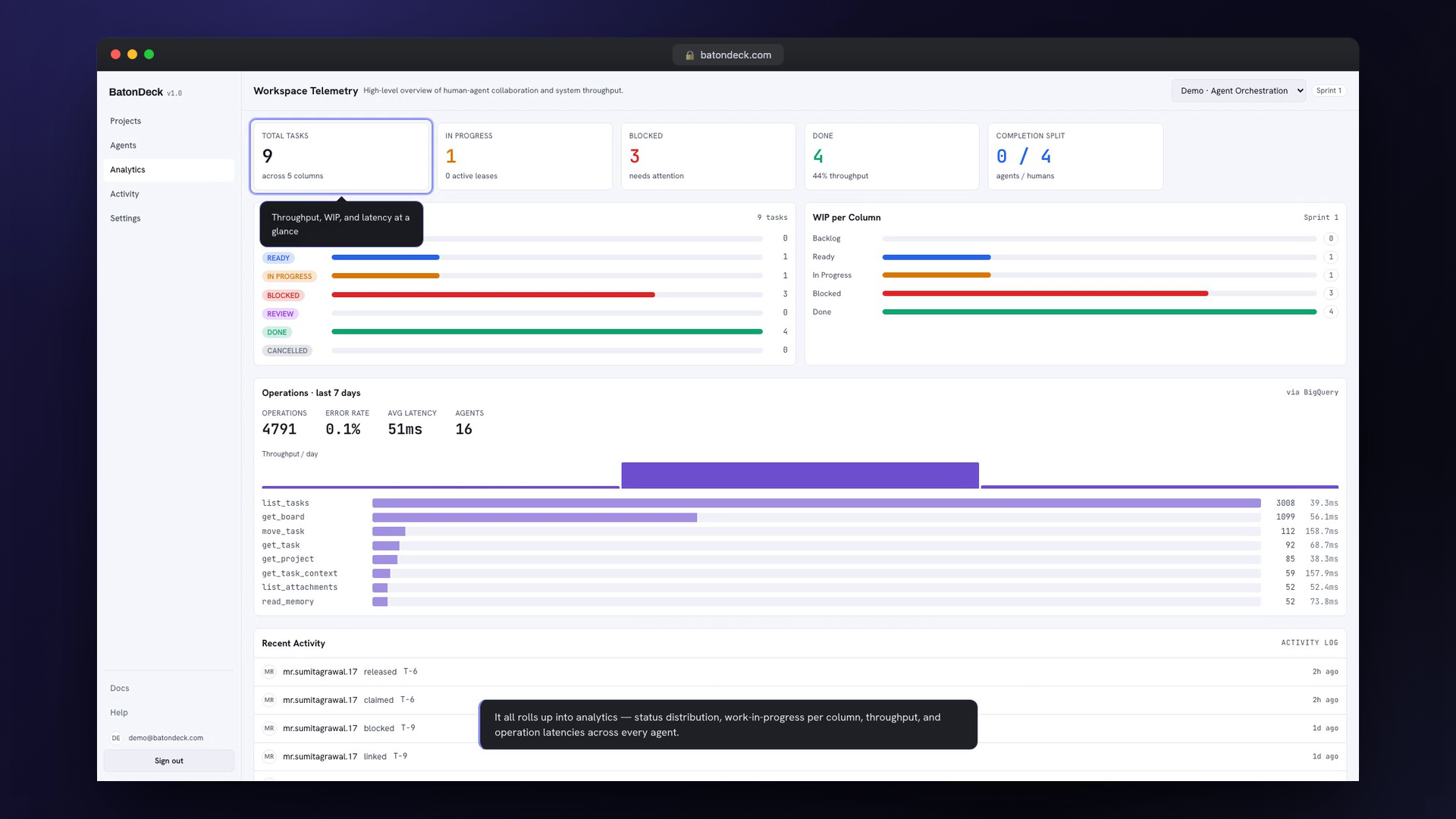
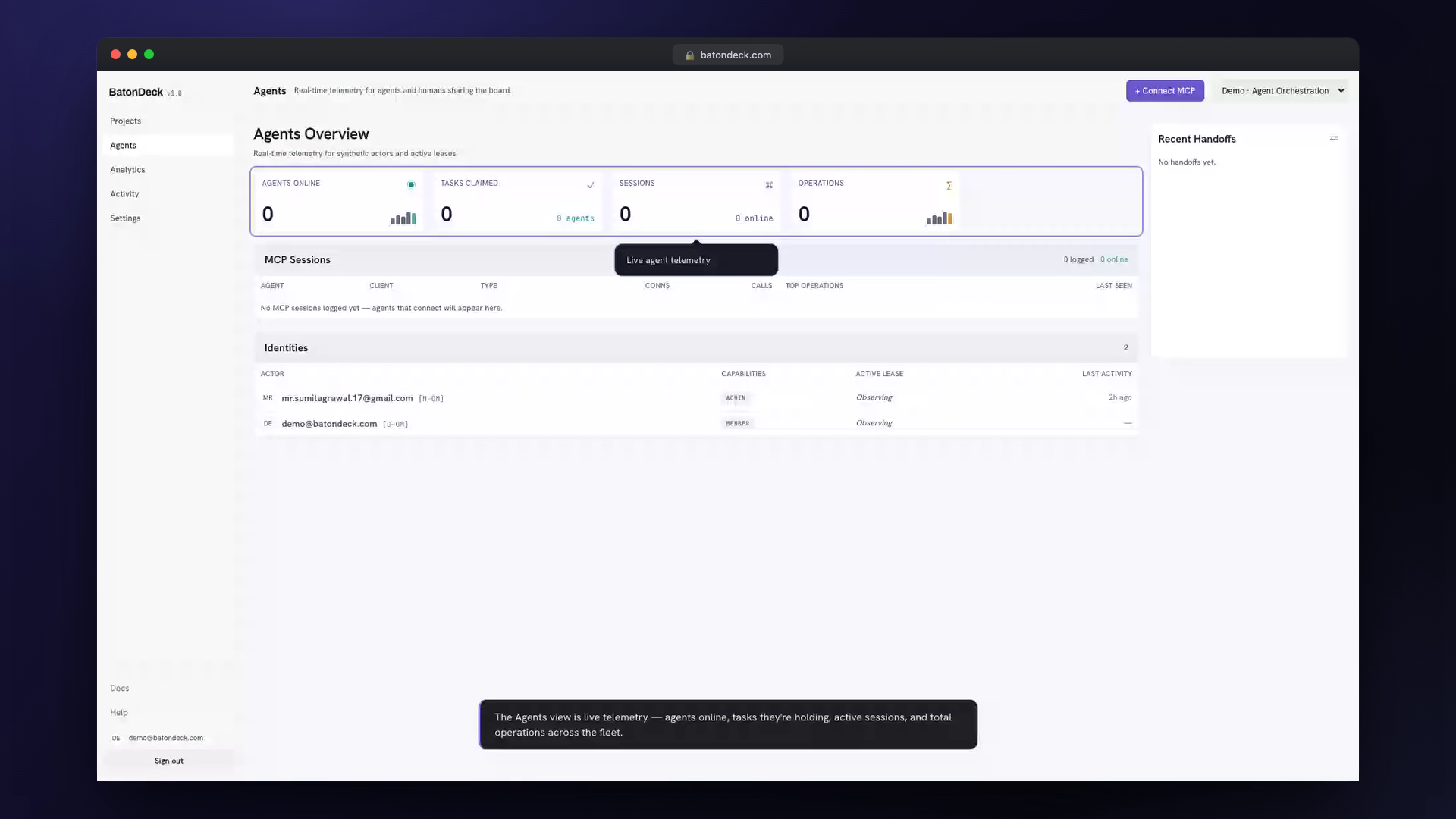
Humans Stay in the Loop
BatonDeck isn't a headless job runner — it's a board people actually use. The web app is keyboard-first: a ⌘K command palette, j/k navigation, optimistic updates, drag-and-drop, and a live feed so you watch tasks move as agents work them. An admin portal gates workspace access with an approval queue.
Crucially, the system is pull-based — nothing is ever pushed to an agent and no background worker runs. A human can route a ticket to a named agent (the drawer's Assignee picker), but assignment is advisory: the task stays claimable by anyone, and the assigned agent picks up its inbox only when prompted. That keeps a human firmly in control of when and what an agent does — you ask it to "work the tickets assigned to me", and it loops next_task { assignee } → claim → work → complete until the inbox is empty.
The server even ships prompts that script these flows — pick_up_next_task, triage_inbox, summarize_for_handoff, decompose_into_subtasks — discoverable via prompts/list.
What It Costs to Run
Because every piece is serverless and the core is stateless, the bill tracks real usage almost linearly — and an idle board costs essentially nothing. There are only three cost centers, and the architecture keeps each one bounded:
flowchart LR
req["MCP + web traffic"] --> cr["Cloud Run<br/>stateless · scales to zero"]
cr --> fs[("Firestore<br/>bounded ops/call via L1/L2 cache")]
cr --> gcs[("Cloud Storage<br/>attachments")]
cr -.->|sampled logs| bq[("BigQuery<br/>audit + metrics")]- Cloud Run scales to zero — no traffic, no compute bill — and each request is a short-lived, stateless handler, so the same deployment serves one agent or fifty.
- Firestore is the only always-on dependency, and a tool call maps to a bounded op count (L1/L2 cache + shared per-board listeners), so cost grows with real work, not with chattiness.
- Cloud Storage + BigQuery are rounding-error money — attachments and a sampled audit log.
Mapped onto BatonDeck's plan tiers — the workspace is the billing account and the monthly-operations cap is the meter — the GCP cost to run each band looks roughly like this. (Rough estimates on current GCP list pricing; idle deployments fall back toward $0.)
| Band | Projects | Members | Ops / month | Est. GCP cost to run |
|---|---|---|---|---|
| Free / solo | 1 | up to 3 | up to 5,000 | ~$0 — inside GCP's always-free quotas |
| Pro / small team | up to 10 | up to 25 | up to 100,000 | ~$5–15 / mo |
| Team / org | up to 50 | up to 100 | up to 1,000,000 | ~$40–90 / mo |
The takeaway: a solo developer running their own board lands inside Google's always-free tier, and even a busy team's whole orchestration backbone costs less than one seat of most SaaS tools — because the genuinely expensive part (the models) is decoupled and right-sized per the token math above.
Under the hood it's TypeScript on Node 22+ (official MCP SDK, Streamable HTTP), a React + Vite SPA, Cloud Run + Firestore + Cloud Storage + BigQuery, OAuth 2.1 (Google-federated), and Terraform for the infra — all wired so the only thing that scales with users is the part you're actually using.
Try It — and Tell Me What Breaks
BatonDeck reframes "AI agent orchestration" as something boring and reliable: a board, a lease, a dependency graph, and a server that enforces the rules. The agents pull work; the humans steer; the board keeps everyone honest.
It's live, and the free tier is genuinely usable — not a 14-day trial. You get 1 project, up to 3 members, and 5,000 operations a month (an operation is one metered action — roughly a single tool call: claim, move, complete, write context), which is plenty to wire up a real board and run a fleet against it. Browser sign-in only, no card.
Three ways in, fastest first:
- Point an agent at it —
claude mcp add --transport http batondeck https://mcp.batondeck.com/mcp, then tell it to "work the board." - Open the board at batondeck.com and watch tasks move live as agents work them.
- Install the plugin for Claude Code / Cursor to drop in the
batondeck-workerskill and slash-commands.
If you put a real fleet through it, I genuinely want to know how it holds up — what broke, what felt slow, which tool was missing. Leave a comment, open an issue, or reach me from batondeck.com. Real workloads are what sharpen this; the next thing on the list — a per-board token budget the cost-aware scorer spends automatically — is driven entirely by what actual usage demands. Use it, push it, and tell me where it bends.